


رغم أن OpenAI قررت عدم إصدار النسخة الثانية من النموذج الجديد للبرمجة اللغوية الى العامة أو للأغراض التجارية. و ذلك لإعتقاد العديد أن إستخدام النموذج لأغراض غير معروفة قد يكون خطيراً، الا أنهم قاموا بطرح إصدارهم الجديد للعامة. حيث يمكن للعديد تجربة بناء تطبيقات عملية أو تجريبية على النموذج عن طريق مخاطبته بإستخدام، اي بي اي API أو مخاطبة واجهة التطبيق برمجياً. أي أن النموذج غير مفتوح المصدر. و قد طرحت الشركة مؤخراً اسعار الاستخدام، و هي أسعار وجدها البعض مقبولة.
سوف نقوم بعرض العديد من الأمثلة لتطبيقات قد تكون غير قابلة للتصديق للوهلة الأولى. ولكن بدايةً دعونا نتطرق لهذا العمل بإختصار، حسب ما نشر في البحث من قبل الشركة.
ما نشر في البحث ورقة العمل
أظهرت الأعمال الأخيرة مكاسب كبيرة في العديد من مهام ومعايير البرمجة اللغوية العصبية المعروفة باسم NLP. من خلال التدريب المسبق على مجموعة كبيرة من النص او ما هو معروف باسم corpus متبوعًا بضبط دقيق لمهمة محددة. على الرغم من أن هذه الطريقة عادةً ما تكون محايدة للمهام في الهندسة، إلا أنها لا تزال تتطلب مجموعات بيانات صقل خاصة بالمهمة تتكون من آلاف أو عشرات الآلاف من الأمثلة. على النقيض من ذلك، يمكن للبشر عمومًا أداء مهمة لغوية جديدة من أمثلة قليلة فقط أو من تعليمات بسيطة، وهو أمر لا تزال أنظمة البرمجة اللغوية العصبية الحالية تكافح من أجله.
نموذج اللغة الجديد المعتمد على Few-Shot أو المتعلم قليل-اللقطات
نوضح هنا أن توسيع نطاق النماذج اللغوية يُحسِّن إلى حد كبير من أداء المهام الحيادية وقليلة اللقطات، بل ويصل أحيانًا إلى القدرة التنافسية باستخدام مناهج الصقل المتطورة السابقة. على وجه التحديد، قام الباحثون بتدريب النموذج الجديد للبرمجة اللغوية GPT-3، نموذج لغة الانحدار التلقائي مع 175 مليار معلمة أو متغير، أكثر من 10 أضعاف من أي نموذج لغة سابق، ويختبر أدائه في إعداد عدد قليل من اللقطات.
بالنسبة لجميع المهام ، يتم تطبيق النموذج الجديد للبرمجة اللغوية GPT-3 دون أي تحديثات متدرجة أو ضبط دقيق، مع تحديد المهام والعروض التوضيحية قليلة اللقطات فقط عبر تفاعل النص مع النموذج. تحقق GPT-3 أداءً قويًا في العديد من مجموعات بيانات البرمجة اللغوية العصبية، بما في ذلك مهام الترجمة ، والإجابة على الأسئلة، وإغلاق المهام. بالإضافة إلى العديد من المهام التي تتطلب تفكيرًا سريعًا أو تكييفًا للمجال، مثل فك تجميع الكلمات، باستخدام كلمة جديدة في الجملة، أو إجراء العمليات الحسابية المكونة من 3 أرقام.
مقالات غاية في الدقة، يصعب تمييزها
في الوقت نفسه، يقوم الباحثون أيضًا بتحديد بعض مجموعات البيانات حيث لا يزال التعلم القليل-اللقطات لـ النموذج الجديد للبرمجة اللغوية GPT-3 يكافح، بالإضافة إلى بعض مجموعات البيانات حيث يواجه GPT-3 مشكلات منهجية تتعلق بالتدريب على مجموعات الويب الكبيرة. أخيرًا ، وجدنا أن GPT-3 يمكن أن يولد عينات من المقالات الإخبارية التي يجد المقيمون البشريون صعوبة في تمييزها عن المقالات التي كتبها البشر. نناقش التأثيرات المجتمعية الأوسع لهذه النتيجة و GPT-3 بشكل عام.
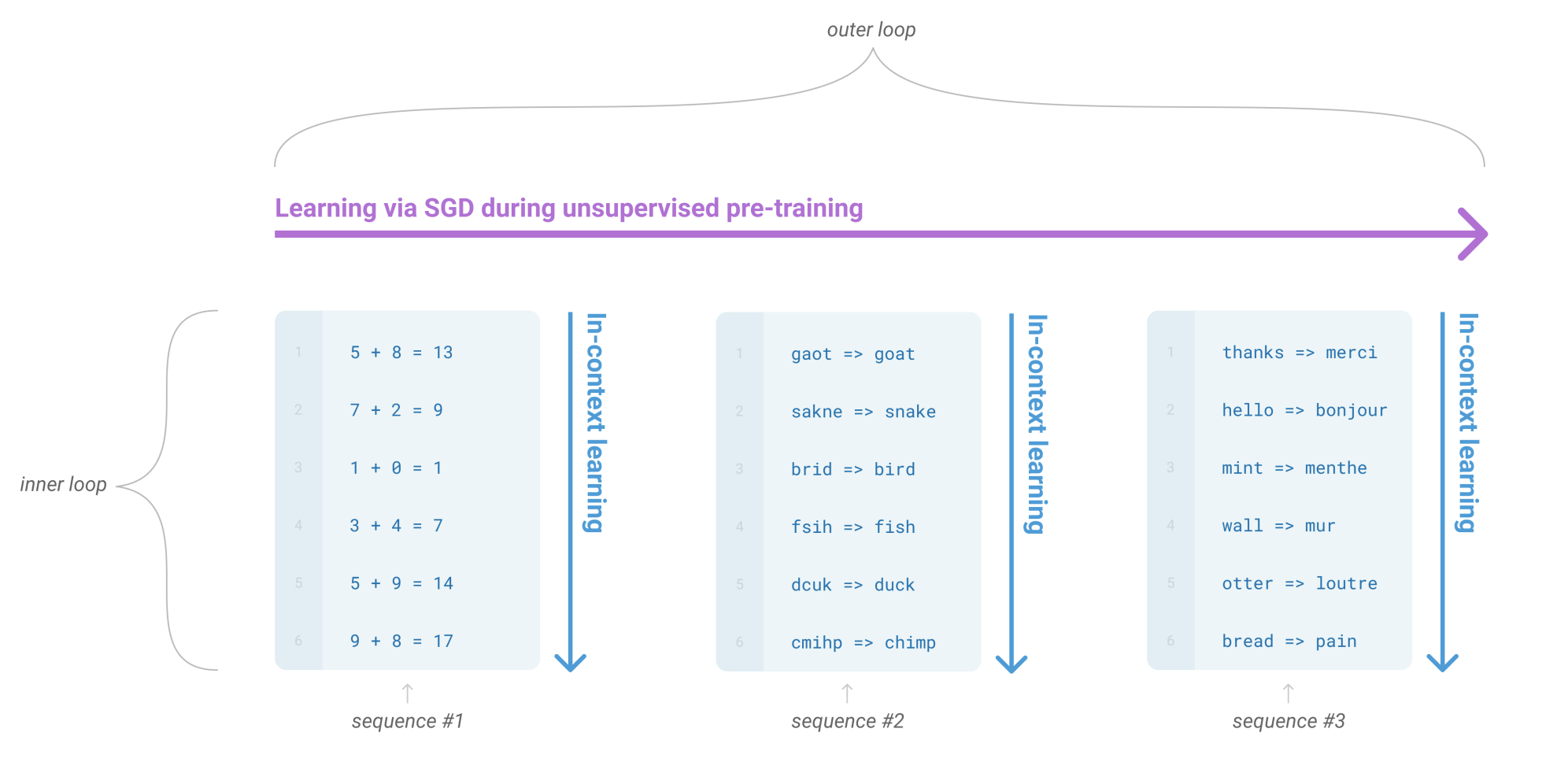
brown2020languageالتدريب-المسبق غير الخاضع للإشراف
أثناء التدريب-المسبق غير الخاضع للإشراف أو المعروف ب unsupervised learning، يطور نموذج اللغة نطاقًا واسعًا من المهارات وقدرات التعرف على الأنماط. ثم يستخدم هذه القدرات في وقت الإستدلال للتكيف أو التعرف بسرعة على المهمة المطلوبة. يستخدم مصطلح “التعلم في السياق” لوصف الحلقة الداخلية لهذه العملية، والتي تحدث داخلها التمرير الأمامي على كل تسلسل. لا يُقصد من التسلسلات في الرسم البياني السابق أن تكون ممثلة للبيانات التي تم مشاهدتها في النموذج أثناء التدريب المسبق، ولكن الغرض منه إظهار أنه توجد مهام فرعية متكررة في بعض الأحيان ضمن تسلسل واحد.

تستخدم النماذج الأكبر حجمًا بشكل متزايد المعلومات الموجودة في السياق. للتوضيح، ان أداء التعلم في السياق في مهمة بسيطة تتطلب من النموذج إزالة الرموز العشوائية من كلمة، سواء مع أو بدون وصف مهمة اللغة الطبيعية. توضح “منحنيات التعلم في السياق” الأكثر حدة للنماذج الكبيرة تحسين القدرة على تعلم مهمة من المعلومات السياقية. نرى سلوكًا مشابهًا نوعيًا عبر نطاق واسع من المهام.
تطبيقات النموذج الرهيبة
أدوات التخطيط و بناء التطبيقات
١. منشئ تنسيق صفحات الوب
٢. إنشاء تصميم التطبيق من الوصف
٣. بناء تطبيق قائمة المهام بلغة React
٤. مكون React يعتمد على اسم المتغير وحده
٥. ينشئ GPT-3 مقاييس ألوان من اسم اللون أو الرموز التعبيرية
٦. إنشاء موقع الويب من الوصف
البحث وتحليل البيانات
٧. الإجابة على الأسئلة ومحرك البحث
٨. زيادة المعلومات في الجداول
٩. إنشاء الرسوم البيانية من الوصف
١٠. توليد الرسوم البيانية وتحديثها بشكل متكرر
المنطق العام
١١. أسئلة الفيزياء
١٢. GPT-3 في مجال الرياضيات
١٣. الرد على الأسئلة الطبية
١٤. التعامل مع الأسئلة غير المنطقية
١٥. أسئلة المنطق
١٦. العمل على الأسئلة في خطوات متعددة
١٧. تحديد مكونات الغذاء وصحته من الصورة
١٨. علم النفس: النمط العصبي -> ترجمة التوحد
و العديد من الأمثلة الأحرى في هذه المكتبة من جيت هب
قد يوفر اتجاه آخر حديث في نمذجة اللغة طريقة للمضي قدمًا. في السنوات الأخيرة زادت قدرة النماذج اللغوية بشكل كبير، من 100 مليون متغير إلى 300 مليون معلمة، إلى 1.5 مليار معلمة ، إلى 8 مليار معلمة مليار معلمة، وأخيراً 17 مليار معلمة. جلبت كل زيادة تحسينات في تركيب النص مهام البرمجة اللغوية العصبية، وهناك أدلة تشير إلى أن فقدان السجل، الذي يرتبط جيدًا بالعديد من مهام المصب/السجل، يتبع الاتجاه السلس للتحسين مع المقياس. بما أن التعلم في السياق ينطوي على استيعاب العديد من المهارات و المهام ضمن معايير النموذج، فمن المعقول أن قدرات التعلم في السياق قد تظهر قوية بالمثل بالتناسب مع الحجم.
النهج المتبع لبناء النموذج
التالي هو سرد للنهج المتبع حسب ما نشر في ورقة العمل من اوبن اه اي:
قبل التدريب، بما في ذلك النموذج والبيانات والتدريب، مشابه للعملية الموضحة في ورقة بحث Alec Radford، مع زيادة مباشرة نسبيًا في حجم النموذج وحجم مجموعة البيانات وتنوعها ومدة التدريب. استخدامنا من التعلم في السياق مشابه أيضًا لـه، ولكن في هذا العمل نستكشف بشكل منهجي إعدادات مختلفة للتعلم في السياق. لذلك، نبدأ هذا القسم بتحديد ومقارنة الإعدادات المختلفة بشكل صريح، أننا سنقوم بتقييم GPT-3. يمكن اعتبار هذه الإعدادات مستلقية على ملف سلسلة لمقدار البيانات الخاصة بالمهمة التي يميلون إلى الاعتماد عليها. على وجه التحديد، يمكننا تحديد أربع نقاط على الأقل في هذا الشأن:
(Fine-Tuning (FT
كان الضبط الدقيق (FT) هو النهج الأكثر شيوعًا في السنوات الأخيرة، ويتضمن تحديث الأوزان نموذج مدرب مسبقًا من خلال التدريب على مجموعة بيانات خاضعة للإشراف خاصة بالمهمة المطلوبة. عادةً من آلاف إلى يتم استخدام مئات الآلاف من الأمثلة المصنفة. الميزة الرئيسية للضبط الدقيق هي الأداء القوي على العديد من المعايير. العيوب الرئيسية هي الحاجة إلى مجموعة بيانات كبيرة جديدة لكل مهمة، وإمكانية استغلال السمات الزائفة لـبيانات التدريب، مما قد يؤدي إلى مقارنة غير عادلة مع الأداء البشري. في هذا العمل لا نقوم بضبط GPT-3 لأن تركيزنا ينصب على الأداء الحيادي للمهام، ولكن يمكن أن يكون النموذج الجديد للبرمجة اللغوية GPT-3 تم ضبطها من حيث المبدأ وهذا اتجاه واعد للعمل في المستقبل.
(Few-Shot (FS
لقطات قليلة (FS) هو المصطلح الذي سنستخدمه في هذا العمل للإشارة إلى الإعداد حيث يتم إعطاء النموذج القليل عروض توضيحية للمهمة في وقت الاستدلال كتكييف، ولكن لا يُسمح بتحديثات الوزن. بالنسبة لمجموعة بيانات نموذجية ، يحتوي المثال على سياق وإكمال مرغوب (على سبيل المثال جملة إنجليزية وترجمة فرنسية)، وأعمال قليلة اللقطات من خلال إعطاء أمثلة K للسياق و إكمال، ثم مثال نهائي واحد للسياق، مع النموذج المتوقع أن يوفر الإكمال.
عادةً ما يتم تعيين K في النطاق من 10 إلى 100 لأن هذا هو عدد الأمثلة التي يمكن احتواؤها في نافذة سياق النموذج. تتمثل المزايا الرئيسية للقطات القليلة في تقليل الحاجة إلى البيانات الخاصة بالمهمة و تقليل القدرة على تعلم توزيع ضيق للغاية من مجموعة بيانات صقل كبيرة ولكن ضيقة. العيب هو أن النتائج من هذه الطريقة كانت حتى الآن أسوأ بكثير من أحدث النماذج. أيضًا، لا تزال هناك حاجة إلى كمية صغيرة من البيانات الخاصة بالمهمة. كما هو مبين بالاسم، قليلة الطلقات التعلم كما هو موضح هنا لنماذج اللغة يرتبط بالتعلم القليل اللقطات كما هو مستخدم في سياقات أخرى في – كلاهما يشتمل على التعلم بناءً على توزيع واسع للمهام (في هذه الحالة ضمنيًا في بيانات ما قبل التدريب) ثم التكيف بسرعة مع مهمة جديدة.
(One-Shot (1S
اللقطة الواحدة (1S) هي نفسها اللقطات القليلة باستثناء أنه يُسمح بمظاهرة واحدة فقط ، بالإضافة إلى اللقطة الطبيعية وصف اللغة للمهمة، كما هو موضح في الشكل التالي. السبب في التمييز بين اللقطة الواحدة واللقطات القليلة و نقطة الصفر (أدناه) هي أنها تطابق الطريقة التي يتم بها توصيل بعض المهام إلى البشر.
على سبيل المثال، عند مطالبة البشر بإنشاء مجموعة بيانات لخدمة عامل بشري (على سبيل المثال ميكانيكي)، من الشائع تقديم عرض توضيحي واحد للمهمة. على النقيض من ذلك ، يصعب أحيانًا التواصل محتوى إذا لم يتم إعطاء أمثلة.
(Zero-Shot (0S
هي نفسها اللقطة الواحدة باستثناء أنه لا يُسمح بأي عروض، ولا يُعطى النموذج إلا تعليمات لغة طبيعية لوصف المهمة. توفر هذه الطريقة أقصى قدر من الراحة والإمكانيات المتانة وتجنب الارتباطات الزائفة (ما لم تحدث على نطاق واسع جدًا عبر مجموعة كبيرة من بيانات ما قبل التدريب)، ولكنها أيضًا الإعداد الأكثر صعوبة. في بعض الحالات قد يكون الأمر صعبًا على البشر لفهم تنسيق المهمة بدون أمثلة سابقة، لذلك يكون هذا الإعداد في بعض الحالات “صعبًا بشكل غير عادل”.




