بدائل أسرع للانتشار العكسي

في الستينيات، توصل أكاديميون من مجموعة جامعات أمريكية إلى نظرية الانتشار العكسي. إنها خوارزمية ستُستخدم فيما بعد على نطاق واسع لتدريب الشبكات العصبية. أنظمة الحوسبة مستوحاة بشكل غامض من الشبكات العصبية البيولوجية التي تشكل أدمغة الحيوانات. برزت نظرية الانتشارالعكسي في عام 2010 في ضوء ظهور أنظمة حوسبة قوية ورخيصة، مما أدى إلى مكاسب في التعرف على الكلام ورؤية الكمبيوتر ومعالجة اللغة الطبيعية.
في أوائل شهر ديسمبرالحالي، تم اقتراح العشرات من البدائل للانتشارالعكسي التقليدي خلال ورشة عمل في مؤتمر NeurIPS 2020 . استفادت بعض الأجهزة مثل الدوائر الضوئية لتعزيز كفاءة الانتشار العكسي، بينما اعتمد البعض الآخر نهجًا أكثر مرونة ونمطية للتدريب.
يتضمن أبسط أشكال الانتشار العكسي حساب التدرج اللوني – خوارزمية التحسين التي تُستخدم عند تدريب نموذج التعلم الآلي – لوظيفة الخسارة فيما يتعلق بأوزان النموذج. وظيفة الخسارة هي طريقة لتقييم مدى جودة نماذج خوارزمية معينة لمجموعة بيانات معينة. تتكون الشبكات العصبية من خلايا عصبية مترابطة تتحرك من خلالها البيانات وتتحكم الأوزان في الإشارة بين خليتين عصبيتين. وتحدد مدى تأثير البيانات التي يتم إدخالها في الشبكة سيكون على النواتج التي تخرج منه.
الانتشارالعكسي
يعد الانتشارالعكسي أو ال backpropagation فعالًا، مما يجعل تدريب شبكات متعددة الطبقات تحتوي على العديد من الخلايا العصبية أثناء تحديث الأوزان لتقليل الخسارة ممكناً. كما أشرنا سابقًا، فإنه يعمل عن طريق حساب التدرج اللوني لوظيفة الخسارة فيما يتعلق بكل وزن من خلال ما يُعرف بقاعدة السلسلة. وحساب التدرج اللوني طبقة واحدة في كل مرة والتكرار للخلف من الطبقة الأخيرة لتجنب الحسابات الزائدة عن الحاجة.
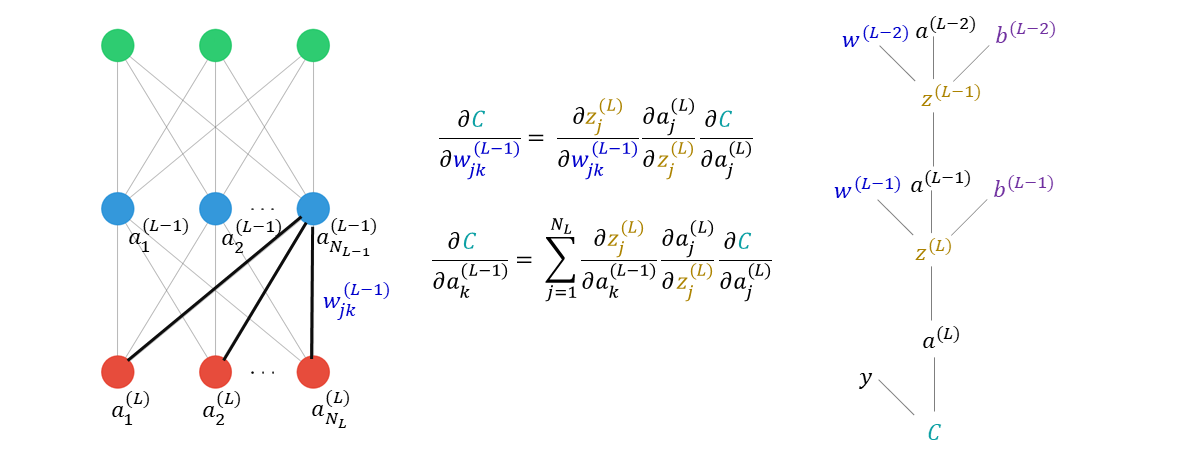
محدودية النظرية
ولكن على الرغم من جميع مزاياها، فإن الانتشارالعكسي محدود للغاية فيما يمكن أن تحققه حتى نقطة معينة. على سبيل المثال، كما يشير عالم الرياضيات أنتوني ريبيتو، فإن خاصية الانتشارالعكسي تجعل من المستحيل التعرف على “كوكبة” من ميزات مجموعة البيانات. عندما يصنف نظام رؤية الكمبيوتر الذي تم تدريبه باستخدام الانتشارالعكسي كائنًا في صورة – على سبيل المثال، “حصان” – لا يمكنه توصيل الميزات الموجودة في الصورة التي أدت به إلى هذا الاستنتاج بسبب فقد هذه المعلومات. تقوم خاصية الانتشارالعكسي أيضًا بتحديث طبقات الشبكة بالتتابع، مما يجعل موازاة عملية التدريب صعبة و أطول.
عيب آخر للانتشار العكسي هو ميله لأن يصبح عالقًا في الحدود الدنيا المحلية لوظيفة الخسارة. رياضياً، الهدف من تدريب النموذج هو التقارب مع الحد الأدنى العام. النقطة في دالة الخسارة حيث قام النموذج بتحسين قدرته على إجراء التنبؤات. ولكن غالبًا ما توجد تقديرات تقريبية للحد الأدنى العالم نقاط قريبة من المستوى الأمثل. ولكن ليس دقيقًا – يجدها الانتشارالعكسي بدلاً من ذلك. هذه ليست مشكلة دائمًا، ولكنها قد تؤدي إلى تنبؤات غير صحيحة من جانب النموذج.
محاذاة
كان يعتقد ذات مرة أن الأوزان المستخدمة للانتشار للخلف عبر الشبكة يجب أن تكون هي نفسها الأوزان المستخدمة للانتشار إلى الأمام. لكن هناك طريقة تم اكتشافها مؤخرًا تسمى محاذاة التغذية الراجعة المباشرة تظهر أن الأوزان العشوائية تعمل بشكل جيد. لأن الشبكة تتعلم بشكل فعال كيفية جعلها مفيدة. هذا يفتح الباب لموازاة التمريرة الخلفية، مما يقلل من وقت التدريب واستهلاك الطاقة حسب الحجم.
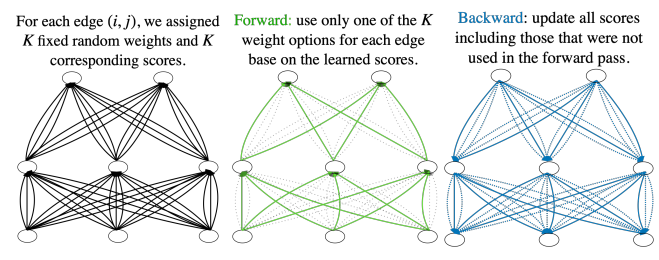
في الواقع، في ورقة تم تقديمها إلى ورشة عمل في نفس المؤتمر، اقترح المؤلفون المشاركون شبكات “ماكينات القمار”. حيث تحتوي كل “بكرة” – أي الاتصال بين الخلايا العصبية – على مجموعة ثابتة من القيم العشوائية. تقوم الخوارزمية “بتدوير” البكرات للبحث عن مجموعات “فائزة” .أو عن مجموعات مختارة من قيم الوزن العشوائية التي تقلل من الخسارة المحددة. تظهر النتائج أن تخصيص عدد قليل من القيم العشوائية لكل اتصال، مثل ثماني قيم لكل اتصال، يحسن الأداء مقارنة بالنماذج الأساسية المدربة.
في ورقة أخرى ادعى باحثون في لايت أون، وهي شركة ناشئة تعمل على تطوير أجهزة الحوسبة الضوئية ، أن محاذاة التغذية الراجعة يمكن أن تدرب بنجاح مجموعة من أحدث هياكل التعلم الآلي، مع أداء قريب من الانتشار العكسي الدقيق. بينما يقر الباحثون بأن تجاربهم تتطلب موارد سحابية “كبيرة” . فإنهم يقولون إن العمل يوفر “وجهات نظر جديدة” قد “تفضل تطبيق الشبكات العصبية في المجالات التي كان يتعذر الوصول إليها سابقًا بسبب القيود الحسابية”.
لكن المحاذاة ليست حلاً مثاليًا، في حين أنها تدرب بنجاح نماذج مثل Transformers. إلا أنها فشلت بشكل ملحوظ في تدريب الشبكات التلافيفية وهو الشكل السائد لنموذج رؤية الكمبيوتر.
أجهزة جديدة و مزايا عديدة
ربما يكون البديل الأكثر جذرية للتوسع العكسي المقترح حتى الآن يتضمن أجهزة جديدة مصممة خصيصًا لمحاذاة التغذية الراجعة. هذا ما نشر في دراسة تم إرسالها إلى ورشة العمل من قبل فريق آخر في لايت أون. يصف المؤلفون المشاركون مسرّعًا ضوئيًا قادرًا ظاهريًا على حساب الإسقاطات العشوائية التي تحتوي على تريليونات من المتغيرات المختلفة. يزعمون أن أجهزتهم – معالج فوتوني – لا تعرف الهندسة المعمارية وربما تكون خطوة نحو بناء أنظمة قابلة للتطوير لا تعتمد على الانتشار العكسي.
تعد الدوائر الضوئية المتكاملة، التي تشكل أساس شريحة لايت أون، بمجموعة من المزايا على نظيراتها الإلكترونية. فهي لا تتطلب سوى كمية محدودة من الطاقة لأن الضوء ينتج حرارة أقل مما ينتج عن الكهرباء. كما أنها أقل عرضة للتغيرات في درجة الحرارة المحيطة والمجالات الكهرومغناطيسية والضوضاء الأخرى. تم تحسين وقت الاستجابة في التصميمات الضوئية حتى 10000 مرة مقارنةً بمكافئات السيليكون عند انخفاض مستويات استهلاك الطاقة.”أوامر من حيث الحجم”، علاوة على ذلك ، تم قياس أعباء عمل نموذجية معينة تعمل أسرع 100 مرة مقارنةً بأحدث الرقائق الإلكترونية.
ولكن من الجدير بالذكر أن أجهزة لايت أون ليست محصنة ضد قيود المعالجة الضوئية. تتطلب الدوائر الضوئية السريعة ذاكرة سريعة. ومن ثم هناك مسألة تغليف كل مكون – بما في ذلك الليزرات والمعدِّلات والمُجمِّعات الضوئية – على رقاقة رقاقة صغيرة. بالإضافة إلى ذلك، تبقى الأسئلة حول أنواع العمليات غير الخطية. وهي اللبنات الأساسية للنماذج التي تمكنهم من عمل تنبؤات، والتي يمكن تنفيذها في المجال البصري.
التقطير
هناك إجابة أخرى تتضمن تقسيم الشبكات العصبية إلى أجزاء أصغر وأكثر قابلية للإدارة. في دراسة بحثية، اقترح الباحثون تقسيم النماذج إلى شبكات فرعية تسمى الأحياء التي يتم تدريبها بعد ذلك بشكل مستقل، والتي تأتي مع فوائد التوازي والتدريب السريع.
من جانبهم ، قام الباحثون في قسم علوم الكمبيوتر بجامعة ميريلاند بتدريب الشبكات الفرعية مسبقًا بشكل مستقل قبل تدريب الشبكة بالكامل. لقد استخدموا أيضًا آلية تنبيه بين الشبكات الفرعية للمساعدة في تحديد الطريقة الأكثر أهمية (المرئية أو الصوتية أو النصية) خلال السيناريوهات الغامضة، والتي عززت الأداء. في هذا السياق، يشير مصطلح “التنبيه” إلى طريقة تحدد أي أجزاء من تسلسل الإدخال – على سبيل المثال، الكلمات – ذات صلة بكل ناتج.
يقول باحثو جامعة ماريلاند إن نهجهم يمكّن شبكة بسيطة من تحقيق أداء مشابه للهندسة المعمارية المعقدة. علاوة على ذلك، يقولون إنه يؤدي إلى تقليل وقت التدريب بشكل كبير مع مهام مثل تحليل المشاعر والتعرف على المشاعر والتعرف على سمات المتحدث.
تقنيات جديدة قادمة
في عام 2017، قال جيفري هينتون، الباحث في جامعة تورنتو وقسم أبحاث الذكاء الاصطناعي في جوجل في مقابلة مع أكسيوس إنه “يشك بشدة” في التعلم العميق. قال “وجهة نظري هي التخلص من كل شيء والبدء من جديد”. “لا أعتقد أن هذه هي الطريقة التي يعمل بها الدماغ.”
كان هينتون يشير إلى حقيقة أنه مع الانتشارالعكسي، يجب “إخبار” النموذج عندما يرتكب خطأ، مما يعني أنه “خاضع للإشراف” بمعنى أنه لا يتعلم تصنيف الأنماط من تلقاء نفسه. يعتقد هو وآخرون أن التعلم غير الخاضع للإشراف أو الإشراف الذاتي، حيث تبحث النماذج عن أنماط في مجموعة بيانات دون تسميات موجودة مسبقًا، يعد خطوة ضرورية نحو تقنيات ذكاء اصطناعي أكثر قوة.
ولكن بصرف النظر عن ذلك، تستمر القيود الأساسية في تحفيز مجتمع البحث للبحث عن بدائل. إنها الأيام الأولى، ولكن إذا نجحت هذه المحاولات المبكرة، فإن مكاسب الكفاءة يمكن أن توسع من إمكانية الوصول إلى الذكاء الاصطناعي والتعلم الآلي بين كل من الممارسين والمؤسسة.